Pipelining the STUMP¶
Higher performance can be gained if a design is pipelined. Here a task is partitioned into a number of stages, say k. If there is independent hardware for each stage, then k tasks (or instructions) can be processed in parallel, with each task at a different stage of processing. This is usually expressed by a space-time diagram.
If the pipe is empty, the time for the first job to be completed is 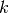 clock cycles; this is referred to as the latency. Once the pipe is full, the throughput is 1 task per clock period. From empty,
clock cycles; this is referred to as the latency. Once the pipe is full, the throughput is 1 task per clock period. From empty, 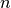 tasks takes
tasks takes 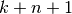 clock periods. If non-pipelined, it would take
clock periods. If non-pipelined, it would take 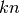 clock periods. So the speedup is
clock periods. So the speedup is 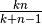 . Usually
. Usually 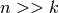 so speed up ~= .
so speed up ~= .
In pipeline design, we need a register to act as the output of a stage so as to provide a constant input to the next stage.
We try to get the time through each stage to be approx equal. We call this a balanced pipeline.
A RISC pipeline for the stump would have 3 stages (fetch, execute, writeback). The instruction register is the output register for the fetch phase. The result register is the output register for the execute stage, and the register bank or memory acts as the output register for the writeback stage. The RISC datapath can thus be the same for non-pipelined and pipelined design.
The only difference is that the pipelined version requires an extra register in its control to hold information to perform the writeback as the instruction register has been overwritten by then.
Pipeline Disruption¶
The flow of instructions through the pipeline can be disrupted because:
Data Dependencies¶
- Can’t write to one register to one instruction and read from it in the next instruction. This is because the value read would be the old value. Either reorganise the instructions to place at least one instruction between them or insert a nop (all zeros).
- Branch instructions cause a change in the instruction flow. In the 3 stage pipeline, fetch the 2 instructions after branch before starting new instr stream. Again, try to reorganise instructions, or if that’s not possible, insert two nops.
- In load and stores, we want to access the memory in the writeback stage simultaneously with fetching an instruction. The pipe must be stoppes to allow the load/store to complete, then in the next clock period restart instruction fetches again.
None of these things happen in non-pipelined design because one instruction at a time is done, so there are no clashes.
Verifying Paths¶
Finally, go back to architectural level to check that all paths needed for pipelined operation are present.
Note that there is much higher path usage in the pipelined system than non-pipelined.